
Xavi Belloso es un Software Engineer con más de veinte años de experiencia, especializado en .Net y enfocado en procesos de mejora de desarrollo. En la charla que ha preparado para el SDSummit, nos cuenta como, en Voxel, hemos afrontado el refactor de nuestra base de código que, a día de hoy, cuenta con veintitrés años de antigüedad.
En 2019 en Voxel estábamos ya en un proceso de transformación que permitiera adaptarnos más rápidamente al cambio. En medio de esta transformación llega el Covid, que nos cambia el enfoque, aunque ya teníamos algunas herramientas que nos ayudaron a llevar más fácilmente esta nueva realidad: llevábamos ya un año trabajando en remoto, y ahora al compartir el ambiente familiar con el laboral, encontramos que tener todo limpio y ordenado, transforma la convivencia en algo más sano y sostenible y con nuestros sistemas, es similar.
¿Cómo se construye un Legacy?
El código legacy, además de ser ese código que no cumple con los principios de clean code, código que en parte no conocemos bien, es código que funciona, que nos hace ganar dinero.
¿Cómo creamos nuestro legacy?: empezamos cuatro personas con una web, funcionaba bien, agregamos funcionalidad, de pronto éramos 20, hay más clientes, agregamos más features, no hay tiempo para “cuidar el producto”, teníamos spikes que se acabaron convirtiendo en nuevos productos…
Como resultado nuestro código tiene una arquitectura monolítica, con lógica en base de datos, es procedural, estático, con dependencias entre componentes y agujeros de conocimiento.
Como consecuencia vimos que algunos problemas iban tomando más fuerza: entrega lenta de features, dependencias entre equipos, nos empieza a costar cada vez más adaptarnos al cambio, nos falta seguridad al interactuar con nuestro código, esa seguridad de la que Edu Ferro nos hablaba en su charla de Small Safe Steps.

Para afrontar estos problemas, nos propusimos como objetivo principal, trabajar en la implementación de mecanismos de integración y entrega continua. Esta iniciativa tenía dos puntos de valor: desde el punto de vista de negocio, entregaríamos funcionalidades de manera más efectiva, alineados con los objetivos de la organización, y desde el punto de vista técnico, podríamos recibir feedback de lo entregado, lo antes posible.
Para avanzar en esta estrategia, fue necesario dar un paso atrás, ver qué teníamos, qué nos faltaba, y entonces saber dónde actuar primero. Ese paso atrás nos dejó ver que debíamos atacar tres frentes: la capacitación técnica, el conocimiento del dominio y la mejora de nuestra plataforma.
Empezamos con la mejora técnica
Para empezar con la mejora técnica, decidimos:
- Formarnos en prácticas XP. Empezamos a hacer pairing, mob programming y diseñamos una estrategia de testing.
- Adoptar una cultura de feedback, usando algunos patrones de sociocracia, como círculos (technical chapter, círculo de producto), enlaces dobles y otros instrumentos como Brown Bags, Comunidad de Prácticas, Newsletter, Tech Blog y este mismo SDSummit.
- Fomentar el cariño por el producto, promoviendo el refactor como hábito, por ejemplo.
Conocer nuestro dominio

También vimos que debíamos mejorar el conocimiento sobre nuestro propio dominio para poder estructurar mejor nuestros equipos de producto. Este fue un proceso que fuimos adaptando según avanzamos:
- Primero enumeramos todas las hojas funcionales o artefactos de producto agrupados por unas categorías técnicas iniciales. Aún no lo podíamos llamar dominios.
- Después, vimos que podíamos usar la técnica de Impact Mapping para alinear nuestros artefactos con la visión de negocio, para eso definimos:
- El objetivo, la meta o el ¿porqué hacemos lo que hacemos?
- Actores (clientes, comerciales, soporte, equipos de producto), quienes participan de esos objetivos.
- Impacto de esos objetivos en los actores.
- Funcionalidades de las que disponíamos para abordar estos impactos, aquí utilizamos los artefactos de producto que habíamos identificado al principio.
- Al terminar con el Impact Mapping, entendimos mejor el sistema y, además, encontramos oportunidades de mejora y nuevas herramientas que ayudarían a solventar algunos problemas.
- El siguiente paso fue agrupar los artefactos en función de los actores y definir la relación entre dichos artefactos (a través de apis, bases de datos, eventos o nugets). En ese momento ya podíamos llamar dominios a esas categorías.
- Luego modelamos casos de uso usando Domain Message Flow Modelling. En un caso de uso dado, un actor inicia el flujo y se incluyen los dominios que intervienen, validamos que nuestra propuesta era correcta o si teníamos que ajustarla.
- Seguidamente, diferenciamos los dominios en tres tipos diferentes: Dominios Core, donde agrupamos la funcionalidad que nos diferencia; Supporting Domains, que es vital para el funcionamiento del core, pero no aporta diferenciación; y Generic Domains, que por lo general son candidatos a ser externalizados.
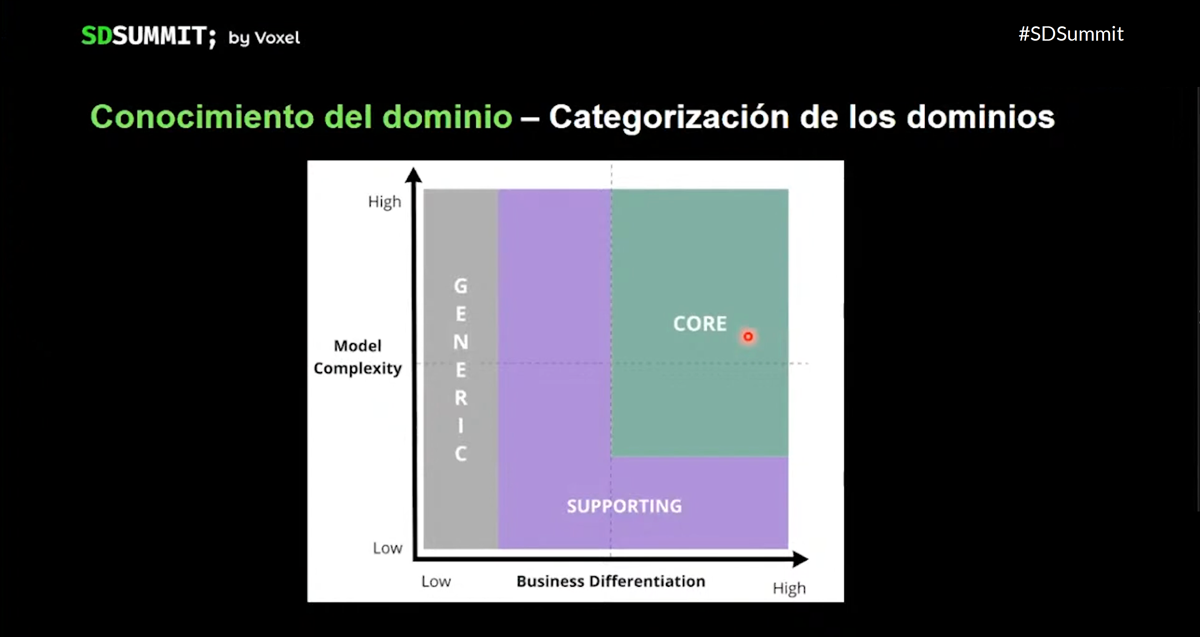
Mejorar nuestra plataforma
Una vez completado este paso atrás, para conocer mejor nuestro dominio, volvemos a enfocarnos en la mejora de la plataforma, empezando primero por nuestro core ¡era momento de refactorizar nuestro legacy!
Para ello planificamos y priorizamos tareas para aumentar nuestro test coverage, orientar nuestra actual arquitectura a una que soporte mejor el modelo DDD y definimos mejor nuestros contratos/interfaces. En este momento, tenemos presente que no reescribiremos todo desde el principio, entonces ¿qué hacemos?, decidimos usar distintos patrones de paralelización:
- Anti-corruption Layer, que nos traduce el legacy para que pueda comunicarse con nuevas funcionalidades que cumplen mejor con un modelo DDD.
- Feature Toggles, nos permiten tener código rápidamente en producción, aunque no se pueda entregar aún al usuario final, o que queramos entregar a usuarios específicos. Debemos tener cuidado, ya que la complejidad puede aumentar rápidamente.
- Strangler Fig Pattern, tal y como nos lo contó Carlos Blé en su charla, nos permite migraciones en paralelo, para poder subir cambios complicados en pequeños pasos y que podemos probar en cada paso. Si es una migración de largo recorrido es importante tener el compromiso de finalizarla.
- Branch by abstraction, como el strangler pattern, pero a un nivel más interno. Creamos un contrato a nivel de componentes, que evita que nos desviemos de ese contrato mientras vamos migrando la implementación poco a poco.
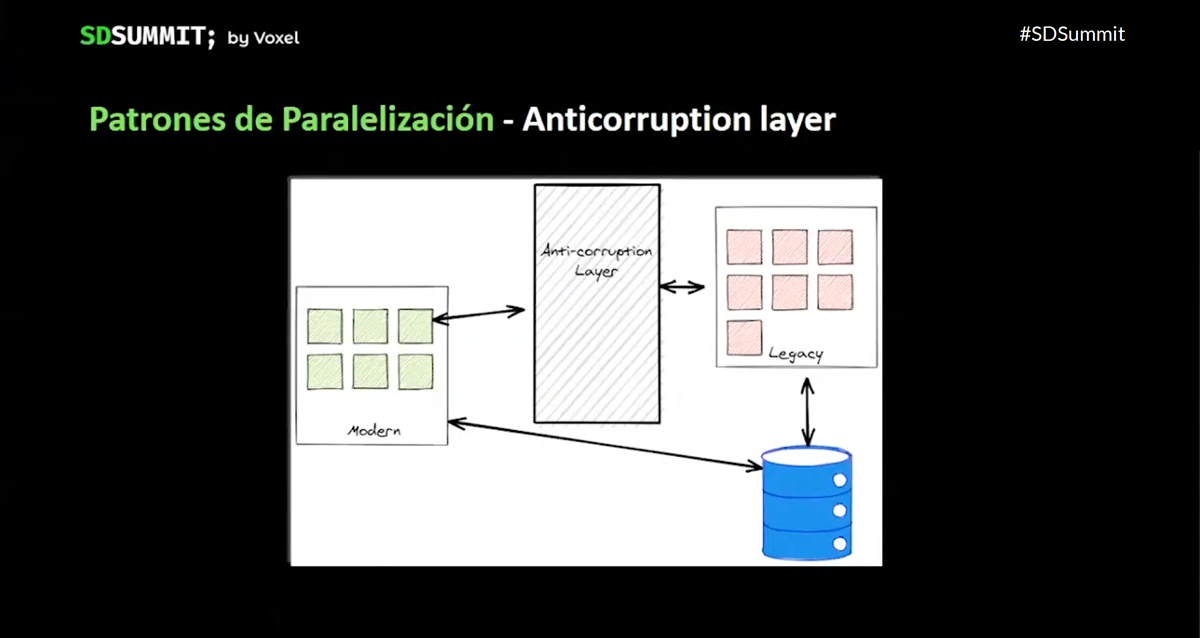
¿Qué hemos aprendido?
Después de descubrir, planificar, priorizar y empezar a llevar nuestro plan a cabo, ¿qué hemos ganado? Hemos notado que las habilidades de los equipos de desarrollo de producto han crecido, tanto técnicas como de cultura, hemos aprendido a compartir y aprender. También conocemos mucho mejor nuestro dominio y en el camino de descubrirlo, hemos aprendido a usar herramientas como Impact Mapping, por ejemplo. Además de conocer mejor nuestro dominio, ahora también sabemos dónde enfocar esfuerzos y conseguir mejor impacto. Finalmente, para poder abordar una tarea tan grande de manera gradual hemos aprendido a usar herramientas de paralelización, abordando el refactor del legacy de manera asumible, segura y continua.
En resumen…
Y si ahora paramos y miramos el camino recorrido, ¿qué conclusiones podemos sacar? Incentivar la cultura de cuidado de nuestro producto es importantísimo, el feedback (humano y técnico) es indispensable, necesitamos trabajar conjuntamente entre las áreas de negocio y técnica, el tamaño de de nuestras User Stories de refactor han de ser de un tamaño asumible, hemos de centrar esfuerzos en nuestros Core Domains. Y debemos ser capaces de hacerlo sin interrumpir el funcionamiento normal del sistema. ¡Sin duda todo lo aprendido (técnicas, cultura, patrones, herramientas), nos ayudará a continuar mejorando!
El video de la charla de Xavi ya está disponible. ¡Os animo a verlo! ¡Enhorabuena por la charla, Xavi!
Sobre el autor:







