
Cuando accedemos a recursos externos desde nuestro código, especialmente si hay una conexión por red por enmedio, es muy probable que nos puedan pasar cosas desagradables. Hace ya más de 20 años, Peter Deutsch y James Gosling describieron lo que llamaron las 8 falacias de los sistemas distribuidos. Aunque las 8 son importantes, para este artículo la más relevante es la primera: La red es fiable. Podeis leer más sobre esto aquí.
Lo que quiere decir esto es que podemos tener errores en nuestro sistema que no sean dados porque el sistema al que llamamos no funcione bien, sino simplemente porque la conexión con él no funciona. Esto puede causar graves problemas a nuestros sitemas si no lo tratamos con cuidado.
Polly
¿Y cómo hacemos esto si somos desarrolladores .NET? Pues nos vamos a apoyar en una magnífica librería llamada Polly. Según pone en su página, Polly es “a .NET resilience and transient-fault-handling library that allows developers to express policies such as Retry, Circuit Breaker, Timeout, Bulkhead Isolation, and Fallback in a fluent and thread-safe manner. Polly targets .NET 4.0, .NET 4.5 and .NET Standard 1.1.”
Esto quiere decir que Polly nos ayudará a detectar errores transitorios y nos proporcionará estratégias para lidiar con ellos. En su versión más simple, lo que vamos a hacer es crear la definición de una política y después ejecutar una acción en el contexto de esa política. Vamos a ver algunas de estas políticas y así veremos como funciona con ejemplos.
Reintentos
Con esta política, lo que le diremos a Pollly es que cuando se encuentre con un tipo de error determinado, reintente la acción que estaba intentando realizar. Lo primero que tendremos que hacer es crear la política de reintentos:
var policy = Policy<A>
.Handle<RetryException>()
.WaitAndRetry(
3,
retryAttempt => TimeSpan.FromSeconds(Math.Pow(2, retryAttempt)),
(result, timeSpan, retryCount, context) =>
{
Console.WriteLine($"Retrying for {retryCount} time, on time {timeSpan} for exception {result.Exception.Message}");
}
);
Como podéis ver, estamos diciéndo a Polly que espere una determinada cantidad de segundos después de cada error y después vuelva a intentar la acción.
Para ejecutar la acción en el contexto de esta política, haremos algo como esto:
var executionCount = 0;
var result = policy.Execute(() =>
{
executionCount++;
Console.WriteLine($"Executing action for {executionCount} time");
throw new RetryException($"Trowing for execution {executionCount}");
return 2;
});
En este caso estamos siempre forzando el error para la demo, pero lo que podría estar pasando es que una llamada HTTP nos ha dado un error que consideremos transitorio, o que a una query a la base datos le haya pasado lo mismo.
Timeout
Con esta política, nos aseguraremos que quien realiza la llamada no tenga que esperar más allá de un determinado tiempo. Esta política nos será útil sobretodo cuando aquello que estemos controlando no tenga una política de timeout implementada por si mismo.
En este caso, la definición de la política sería algo como:
var policy = Policy
.TimeoutAsync(TimeSpan.FromMilliseconds(2500))
y el código que la utiliza algo como:
var cancellationToken = new CancellationToken();
await policy.ExecuteAsync(async (ct) =>
{
Console.WriteLine($"Start Execution at {DateTime.UtcNow.ToLongTimeString()}");
await Task.Delay(10000, ct);
Console.WriteLine($"Finish Execution at {DateTime.UtcNow.ToLongTimeString()}");
}, cancellationToken);
Si ejecutamos este código, veremos que la espera no se alarga más de los 2.5 segundos.
Cache
La política de caché nos permite devolver resultados de una caché cuando estos estén disponibles. Esto nos permitirá no tener que hacer tantas llamadas al otro sistema e incrementará el rendimiento global.
En este caso, la definición de la política sería algo como:
var policy = Policy
.Cache(
memoryCacheProvider,
new SlidingTtl(TimeSpan.FromMinutes(5)),
onCacheGet: (context, key) =>
{
Console.WriteLine($"Get {key} from cache");
},
onCachePut: (Context, key) =>
{
Console.WriteLine($"Put on {key}");
},
onCacheMiss: (context, key) =>
{
Console.WriteLine($"Miss {key}");
},
onCacheGetError: (context, key, exception) =>
{
Console.WriteLine($"Error getting {key}");
},
onCachePutError: (context, key, exception) =>
{
Console.WriteLine($"Error putting {key}");
});
Y un ejemplo de uso:
for (int i = 0; i < 10; i++) { var result = policy.ExecuteAndCapture(context => GetSomething(), new Context("KeyForSomething"));
Console.WriteLine($"Result is {result.Result}");
}
Fallback
Esta política nos permite definir un valor substituto cuando la acción falla. Esto nos permitirá que, aunque la acción falle, nosotros estemos devolviendo un valor que pueda ser utilizado para continuar con nuestro trabajo. Un ejemplo típico de esto es que, si nos falla un servicio de recomendación de, por ejemplo, películas, devolvamos unas películas por defecto.
En este caso la política sería algo como:
return Policy<User>
.Handle<FallbackException>()
.Fallback(() => new User("defaultUser"));
Y el uso algo como:
var result = policy.Execute(() => throw new FallbackException());
Console.WriteLine($"Username is {result.Name}");
En este caso veremos que, aunque la llamada este siempre fallando, la variable result siempre está informada.
Circuit Breaker
El patrón Circuit Breaker es un patrón que fue popularizado por Michael Nygard en su maravilloso libro ReleaseIt. Lo que nos provee el circuit breaker es una manera de devolver rápido un error después de que la operación falle un determinado número de veces. Una vez en este estado, después de un determinado intervalo de tiempo se volverá a hacer la llamada; si ésta se puede realizar, a partir de entonces se volverá a hacer la llamada cada vez. Si falla, se volverá a devolver el error y se volverá a intentar la llamada después del intervalo de tiempo.
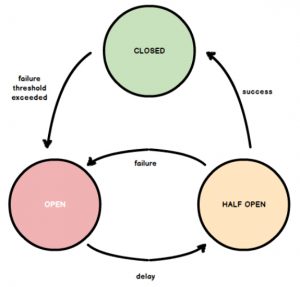
En este caso definiríamos la policy de esta manera:
Action<Exception, TimeSpan> onBreak = (exception, timespan) =>
{
Console.WriteLine($"Breaking because of {exception.Message} after {timespan.TotalSeconds} seconds");
};
Action onReset = () =>
{
Console.WriteLine("It's running again!");
};
var breakerPolicy = Policy
.Handle<BreakerException>()
.CircuitBreaker(1, TimeSpan.FromSeconds(10), onBreak, onReset);
Y podríamos llamarla de esta manera:
for (int i = 0; i < 20; i++) { Console.WriteLine($"Lets call the downstream service at {DateTime.Now.ToLongTimeString()}"); try { breakerPolicy.Execute(ctx => SimulateCallToDownstreamService(ctx),
new Dictionary<string, object>() {{"id", i}});
} catch (Exception ex)
{
Console.WriteLine($"The downstream service threw an exception: {ex.Message}");
}
await Task.Delay(TimeSpan.FromSeconds(2));
}
Wrap policy
Estas políticas son interesantes por si solas, pero lo que da más poder a la librería es poder combinarlas. Un ejemplo de combinación sería el siguiente, en el que estamos uniendo un fallback y un retry, de manera que si después de x reintentos la llamada sigue fallando, devolveremos un valor por defecto:
var wrapPolicy = Policy.Wrap(
FallbackPolicy.GetGenericPolicy(),
RetryPolicy.GetPolicy<User>());
Podéis encontrar combinaciones típicas aquí.
Resumen
En este artículo hemos visto una introducción a Polly, una librería que nos proporciona patrones de resilencia para nuestras aplicaciones .Net. Polly será una gran compañera de viaje a poco que tus aplicaciones se compliquen un poco.







