
Haz que tus sistemas tengan más caché
Conforme avanza la tecnología, los usuarios de aplicaciones web y escritorio somos más impacientes, acostumbrándonos a tener todo en el momento.
Hace tan solo unos años no nos importaba esperar algo más de un minuto para descargarnos y visualizar cualquier imagen desde nuestro navegador.
Pero ahora esto sería impensable. La tecnología nos ha acostumbrado a la inmediatez, y que nuestra aplicación no cumpla las expectativas del usuario puede hacernos perder ventas, clientes o visibilidad.
Según algunos datos recopilados por el servicio Website Hosting, en 2019 el 47% de los usuarios esperaban que una página web cargue en 2 segundos o menos. Las páginas cargadas en este tiempo tienen una conversión del 1.9%, en contra de las que cargan en 6 segundos o más, que tienen una escasa conversión del 0.6%. Podéis consultar este estudio completo aquí.
Pero que no cunda el pánico, las exigencias del consumidor han ido aumentando, pero las herramientas y tecnologías disponibles para paliar estas necesidades también. Uno de los puntos débiles a nivel de velocidad de procesamiento tanto para aplicaciones web como para aplicaciones de escritorio son las bases de datos relacionales. Cuándo estas tienen miles de consultas y millones de registros pueden resultar ‘lentas’, pero ¿es necesario que vayamos a buscar a nuestra bbdd una y otra vez siempre los mismos datos?, ¿podríamos ahorrarnos consultas a nuestra bbdd, y, por lo tanto, mejorar los tiempos de carga? Para ello nos puede ayudar nuestra amiga, la caché.
Pero empecemos por lo básico:
¿Qué es la caché y para qué sirve?
La memoria caché sirve como almacenamiento de datos de alta velocidad. Guarda copias de los datos más usados de forma temporal, para que las siguientes solicitudes se atiendan con mayor rapidez que si se accediera desde el almacenamiento principal.
Cuando se diseña una memoria caché, para maximizar su eficiencia, hay que tener en cuenta las veces que el dato solicitado se encuentra en caché, esto es, el ratio de aciertos y fallos (hits/misses). No es un estándar y dependerá del caso de uso, pero un ratio de aciertos ideal está en torno al 95-99%.
Como se ha comentado, la caché almacena datos de forma temporal, lo que se conoce por TTL (Time To Live), que no es más que el tiempo que estará el dato en caché antes de que se borre. Es importante pensar bien este parámetro, ya que de él dependerá en gran parte la eficiencia del sistema.
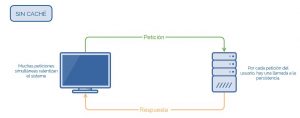
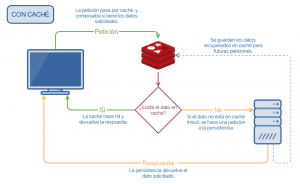
A continuación, podemos ver un par de sistemas simplificados, uno sin caché, y otro con caché, para ver cómo funcionan y qué ventajas tienen:
La caché tiene muchos casos de uso, entre otros:
- Aumento de la velocidad del sistema de gestión de bases de datos. Las bases de datos relacionales son “lentas” cuando trabajan con millones de registros. Los datos innecesarios o antiguos, pueden ralentizar el índice, pudiendo experimentar retrasos y latencia en la respuesta de una consulta. En estos escenarios, las consultas de lectura se pueden almacenar en caché durante una pequeña franja de tiempo. Las bases de datos relacionales también usan su propia caché. Es uno de los casos de uso más populares de almacenamiento en caché.
- Administración de consultas en aplicaciones web/móviles. Las aplicaciones web o móviles con mucho tráfico experimentan muchas llamadas al backend, que suelen terminar siendo consultas de lectura a base de datos. Llamadas como el cálculo sobre pagos ya realizados, datos dinámicos no críticos como el número de seguidores de un usuario, número de retweets, cantidad de espectadores viendo un stream en directo, etc. El almacenamiento en caché se suele usar en estos casos para aliviar la carga.
- Videojuegos. El perfil del jugador y la tabla de clasificación son 2 ventanas que los jugadores ven con mucha frecuencia, especialmente en los juegos multijugador en línea. Con millones de jugadores, es de extrema importancia actualizar y obtener estos datos lo más rápido posible. El almacenamiento en caché es muy efectivo en estos casos.
- Caché en páginas web. Para hacer que la interfaz de una aplicación móvil o web sea liviana y flexible, se pueden crear páginas web dinámicas en el servidor y servirlas a través de la API junto a los datos apropiados. Si esta aplicación tiene millones de usuarios, se pueden publicar páginas web completas creadas desde memoria caché.
¿Qué es Redis?
Redis es un motor de base de datos en memoria de código libre, basado en el almacenamiento en tablas de clave/valor donde cada clave tiene su valor asociado. Una de las principales diferencias con otros sistemas similares, es que Redis admite el almacenamiento de estructuras más complejas y flexibles. Además de poder almacenar strings, permite el almacenamiento de listas, o hashes útiles para representar objetos, entre otros.
Redis normalmente almacena la información en la memoria RAM, pero permite la persistencia de datos mediante snapshots para posibilitar la recuperación de estos en caso de fallos. Gracias a que la información queda almacenada en memoria, en lugar del disco, los tiempos de acceso a los datos son muy superiores a los tiempos de acceso a una base de datos relacional tradicional.
En definitiva, Redis es altamente recomendado cuando la velocidad de acceso y los tiempos de respuestas son críticos para el negocio, o cuando se trabaja con una aplicación en tiempo real, por lo que es una opción óptima para usarla como caché.
Uso e implementación en un proyecto netCore
Vamos a mostrar una implementación de un get/set básico contra Redis en un proyecto netCore. En este ejemplo, no nos vamos a centrar en detalles de implementación, solo mostraremos lo mínimo y aconsejable, según nuestra experiencia, para poder almacenar datos en caché sobre Redis.
En primer lugar, instalaremos el paquete de NuGet Microsoft.Extensions.Caching.StackExchange Redis. Esta librería contiene una implementación para usar la interfaz IDistributedCache de .Net con Redis como backend de almacenamiento de caché. La interfaz IDistributedCache proporciona los métodos necesarios para manipular elementos en la implementación de la caché distribuida, así como Get, Set o Remove.

Una vez instalado el nuget, deberemos añadir el servicio en nuestro Startup.cs:
startup.cs
services.AddStackExchangeRedisCache(options => options.Configuration = Configuration.GetSection("ConnectionStrings")["RedisServer"]);
services.AddSingleton(serviceProvider => new DistributedCacheInterceptor(serviceProvider.GetService(), serviceProvider.GetRequiredService()));
En este fragmento de código podemos ver 2 partes:
- services.AddStackExchangeRedisCache(options => options.Configuration = Configuration.GetSection(«ConnectionStrings»)[«RedisServer»]);
- Aquí estamos agregando, a partir del fichero de settings, la cadena de conexión de nuestro servidor de Redis al servicio de almacenamiento de caché.
- Aquí estamos agregando, a partir del fichero de settings, la cadena de conexión de nuestro servidor de Redis al servicio de almacenamiento de caché.
- services.AddSingleton<IDistributedCache>(serviceProvider => new DistributedCacheInterceptor(serviceProvider.GetService<RedisCache>(), serviceProvider.GetRequiredService<Serilog.ILogger>()));
- En este fragmento de código añadimos el servicio de caché a nuestra aplicación. A resaltar la clase que estamos usando para interceptar este servicio: DistributedCacheInterceptor. Este paso no es necesario pero sí altamente recomendable, ya que sin gran esfuerzo nos permite interceptar todas las llamadas a Redis desde una única clase.
Imaginemos que quisiéramos añadir un registro de log para cada Get que hagamos contra Redis. En vez de hacerlo sobre cada Get que se hace en nuestra aplicación, bastará con tenerlo centralizado en nuestro interceptor
- En este fragmento de código añadimos el servicio de caché a nuestra aplicación. A resaltar la clase que estamos usando para interceptar este servicio: DistributedCacheInterceptor. Este paso no es necesario pero sí altamente recomendable, ya que sin gran esfuerzo nos permite interceptar todas las llamadas a Redis desde una única clase.
Esta clase deberá implementar IDistributedCache. Un posible uso podría ser:
DistributedCacheInterceptor.cs
internal class DistributedCacheInterceptor : IDistributedCache
{
private readonly IDistributedCache _cacheService;
private readonly Serilog.ILogger _logger;
public DistributedCacheInterceptor(RedisCache cacheService, Serilog.ILogger logger)
{
_cacheService = cacheService;
_logger = logger;
}
public byte[] Get(string key)
{
byte[] bytes = null;
try
{
bytes = _cacheService.Get(key);
_logger.Information("GetOperation");
}
catch (Exception ex)
{
_logger.Error($"GetError {ex}");
}
return bytes;
}
En este ejemplo, justo después de hacer el Get contra nuestro Redis (_cacheService.Get(key)), se escribe un registro en log (_logger.Information(«GetOperation»)). Esto aplicaría a todas las los Gets de caché que aparezcan en el sistema.
Por último, queda ver cómo atacamos a la caché desde nuestro código productivo. Si usamos inyección de dependencias, sería tan sencillo como inyectar IDistributedCaché allí dónde queramos realizar alguna operación contra Redis, y llamar al método que necesitemos.
En el ejemplo se comprueba si un dato ya está registrado en caché. En caso afirmativo, recuperamos los datos de esta y nos ahorramos la consulta a bbdd. En caso contrario, obtendremos el valor de bbdd, pero lo almacenaremos en caché para que el próximo acceso sea más rápido.
No olvidemos que tenemos una clase interceptora (DistributedCacheInterceptor) por dónde pasan las peticiones antes de llegar a Redis, por lo que todas las operaciones comunes (como la escritura en log) no serían necesarias realizarlas a este nivel.
MyClass.cs
public class MyClass
{
private readonly IDistributedCache _distributedCache;
public MyClass(IDistributedCache distributedCache)
{
_distributedCache = distributedCache;
}
private string MyFunction(string key, string value)
{
var cacheResponse = _distributedCache.Get(key);
if (cacheResponse != null){
value = Encoding.UTF8.GetString(cacheResponse);
}else{
value = GetFromRepository (key) ;
_distributedCache.Set(key, Encoding.UTF8.GetBytes(value));
}
return value;
}
}
Alerting y observability
Una parte importante de la implementación de un sistema es tener constancia de cómo se está comportando. En el caso de una caché, es importante monitorizar elementos como los ratios de aciertos y fallos o la correcta configuración de los TTL.
Si queremos monitorizar la estabilidad y carga de Redis, tenemos varias opciones. En nuestro caso, usamos RedisInsight, Grafana y Zabbix. Echemos un vistazo a cada una de ellas:
RedisInsight
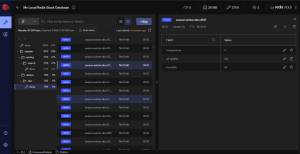
Esta herramienta propia del equipo de Redis, nos permite visualizar e incluso modificar los datos que hay en la caché. Nos permite interactuar mediante consola o interfaz desde el propio software, y tener guardadas varias conexiones a diferentes instancias.
Grafana
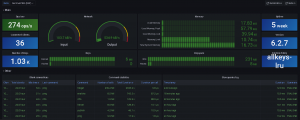
Grafana es una plataforma de observabilidad de código abierto, donde podemos monitorizar sistemas y extraer métricas de infinidad de fuentes. En el caso de Redis, lo tenemos muy fácil porque existe un plugin que nos facilita el sistema de conexión a una instancia de Redis, y nos monta automáticamente el panel de control. Destacar que Grafana nos permite crear alertas que podemos recibir tanto por email como por otros medios como Telegram o Slack.
Zabbix
Zabbix está diseñado para la monitorización de servicios de redes, servidores y hardware. Con esta herramienta podemos ver el estado de salud del host donde está alojado nuestro Redis, pudiendo ver infinidad de datos y como en Grafana, también podemos crear alertas, como llamadas telefónicas o mensajes por email o a sistemas de mensajería.

Conclusiones
En definitiva, hemos visto cómo una caché nos ayuda a aliviar la carga a la persistencia, sobre todo en sistemas sometidos a mucho estrés. Redis es un candidato ideal, ya que se almacena en memoria, convirtiéndola en una caché muy veloz, y su implementación es bastante sencilla.
También hemos visto herramientas con las que podemos dar observabilidad y crear alertas. Ahora solo falta que te animes y lo pruebes.







