

Al igual que otros términos usados en el desarrollo de software, el concepto de observabilidad tiene su origen en otro campo, en este caso, en el de los sistemas de control. Como dual matemático de la controlabilidad, la propiedad que indica si el comportamiento de un sistema se puede controlar desde sus entradas, la observabilidad es la propiedad o la medida de cómo podemos conocer el comportamiento interno de un sistema a partir del conocimiento de sus salidas externas. Dicho en otras palabras, podríamos considerar que la observabilidad es ownership: es habilitarnos y capacitarnos para ser dueños de nuestro código, de nuestros servicios y de nuestra disponibilidad. Es entender completamente nuestros sistemas.
Como bien explica Charity Majors en Observability — A 3-Year Retrospective, es importante saber cómo hemos estado intentando entender nuestros sistemas hasta ahora y los cambios que ha habido para entender por qué es interesante (y necesaria) la observabilidad, y por qué especialmente ahora.
Conceptos
Se dice que la observabilidad en sistemas de software se da gracias a tres grandes pilares: las métricas, los logs y las trazas:
- Las métricas son medidas, representaciones numéricas de algo medido en intervalos de tiempo cuya característica fundamental es que es información agregable. Nos permiten generar histogramas, contadores… Pero no suelen tener asociado un contexto rico o amplio. Generalmente indican qué y cuándo ha pasado algo, pero no exponen información detallada del porqué. Para esto último solemos recurrir al logging.
- Desde que tenemos terminales y lenguajes de alto nivel tenemos logs, tenemos outputs en forma de strings legibles y entendibles para la mayoría de seres humanos. Los logs suelen llevar una información más detallada sobre qué y cuándo ha ocurrido algo.
- Finalmente, pasamos a las trazas, que al final son como logs estructurados con un contexto. Estas trazas se generan a partir del tracing, el seguimiento de una petición desde su inicio hasta su final, lo que nos permite saber qué componentes y servicios se están utilizando en nuestra aplicación. Esto nos facilita resaltar ineficiencias, cuellos de botella, obstáculos en la experiencia del usuario…
Entonces, ¿la observabilidad tiene estos tres pilares? Aquí os vamos a decir que no. Al final estos son solo tres tipos de datos, con los cuales podemos o no lograr tener observabilidad. Podemos convertir las trazas en métricas de series temporales, las métricas en logs…Lo que importa es lo que se hace con los datos, no los datos en sí. Ben Sigelman argumenta más y mejor sobre esto en Three Pillars with Zero Answers.
Observabilidad y monitorización
Llegadas a este punto quizás ya ha surgido la pregunta sobre la relación entre observabilidad y monitorización. ¿La monitorización es observabilidad? ¿Si es monitoreable es observable?
Cuando monitorizamos, al menos en su origen (y ya lo dice la palabra), miramos monitores; miramos una serie de paneles que nos indican en qué estado están nuestros sistemas a partir de sets predefinidos de datos telemétricos. Cuando se da una anomalía y tratamos de averiguar qué está sucediendo, no estamos realmente inspeccionando lo ocurrido siguiendo una secuencia de pistas, estamos saltando directamente a una suposición:
“Miro mis paneles. Veo un pico de errores a las X horas. Qué raro (y qué mal). Parece que se da en un clúster de Y en particular. Ah, la última vez que esto sucedió, fue porque se estaba ejecutando Z. Voy a comprobar si hay algo similar a Z. Mira, aquí está. Confirmado”.
Como comenta Charity Majors en su retrospectiva, es como si todo el sistema fuera todavía una gran caja negra. En un proceso mental como el anterior, vemos que dependemos mucho de múltiples saltos intuitivos y de la biblioteca mental que hayamos ido construyendo con la experiencia de incidencias pasadas. Tenemos que conocer esas posibles causas y saber qué preguntar con antelación cuando miramos los datos.
Quizás el proceso que tendríamos que seguir es otro. Quizás podríamos comenzar preguntándonos simplemente «¿qué ha pasado?» y, a partir de allí, seguir sistemáticamente las migas de datos hasta la solución verificable, sea la que sea. Majors explica que al final lo que implica esto es tener pequeñas hipótesis verificables o refutables una detrás de otra, y eso solo funciona porque puedo desglosar por todas las dimensiones, funciona porque he recopilado los datos en el nivel correcto de abstracción (lo cual es difícil cuando trabajamos con cardinalidades bajas y si se dan agregaciones de los datos previas a su escritura, que es lo que suele pasar con las métricas).
La monitorización es útil cuando podemos predecir la mayoría de los estados en los que entrarían nuestros sistemas, es efectiva cuando las posibles incógnitas son un conjunto estable conocido.
Sin embargo, sabemos que esto es cada vez menos aplicable: que si serverless, que si funciones lambda, que si contenedores y microservicios…Lo más difícil ya no es comprender cómo se ejecuta el “código problemático”, sino encontrar en qué parte del sistema está. Para un sistema con incógnitas predominantemente desconocidas, las herramientas de monitorización no son suficientes. Monitoreable no es observable.
Charity Majors elabora más sobre la importancia de definir claramente el concepto de observabilidad en la más reciente Observability — The 5-Year Retrospective.
Conclusiones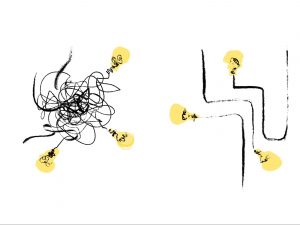
Entonces, ¿qué es un sistema observable? Un sistema es observable en la medida en que se puedan explicar las incógnitas desconocidas siguiendo un hilo que ya está allí. Comprender el sistema sin tener que adivinar, sin tener que hacer coincidir patrones rascando de mi memoria y sin tener que introducir código nuevo para comprender esos estados inesperados.
El tiempo que ahorramos al evitar estas investigaciones a ciegas, al evitar tener que deployar solo para saber algo concreto de un momento concreto, al no estar rompiéndonos la cabeza… Es tiempo que podemos dedicar a desarrollar, a mejorar y a realmente aportar valor.
Pensar en observabilidad también es pensar en curar la información para no tener datos inservibles que consuman recursos innecesariamente. Pensar en observabilidad también es pensar en un proceso de democratización: no solo los desarrolladores, los ingenieros o los técnicos del sistema que sepan de datos telemétricos complejos deberían entender qué está pasando. El valor de la observabilidad se hace realmente patente cuando toda la organización puede obtener las respuestas a sus preguntas y entender cómo funcionan nuestros proyectos, nuestros servicios, nuestros productos.
Sobre la autora
Carolina Zhou, Software Engineer en Voxel. Linkedin. Twitter.







