
Xavi Belloso is a Software Engineer with more than twenty years of experience, specialized in .Net and focused on development improvement processes. In the talk he has prepared for the SDSummit, he tells us how, in Voxel, we have faced the refactor of our twenty-three years old code base.
In 2019 at Voxel, we were already in a transformation process that would allow us to adapt more quickly to changing requirements. In the midst of this transformation arrives the Covid. Nevertheless, we already had some tools that helped us to cope with this new reality more easily: we had already been working remotely for a year, and by sharing the family and working environments, we found that having everything clean and tidy transforms coexistence into something healthier and more sustainable. With our systems, something similar can be applied.
How did we build a Legacy?
The legacy code, in addition to being that code that does not meet the principles of clean code, that code that is unknown to us in certain parts, it’s code that works, that allows us to earn money.
So, how did we create our legacy?: four people started with a website, it worked well, we added functionality, suddenly there were 20 of us, there were more clients, we added more features, there was no time to “take care of the product”, we had spikes that ended up becoming new products …
As a result, our code has a monolithic architecture, with logic defined on the database, it’s procedural, static, with dependencies between components and knowledge holes.
As a consequence, we saw that some problems were becoming bigger: slow feature delivery, dependencies between teams, it became increasingly difficult for us to adapt to change, we lacked security when interacting with our code, that security that Edu Ferro told us about in his Small Safe Steps talk.

To address these problems, we set ourselves a main objective, that was to work on the implementation of continuous integration and continuous delivery mechanisms. This initiative had two points of value: from a business point of view, we would deliver functionalities more effectively, aligned with the organization’s objectives, and from a technical point of view, we could receive feedback on what was delivered, as soon as possible.
To advance in this strategy, it was necessary to take a step back, see what we had already working, what we lacked, and then know where to act first. That step back, let us see that we had to work on three fronts: technical training, knowledge of the domain and improvement of our platform.
We started with the technical improvement
To start with the technical improvement, we decided:
- To train in XP practices, we began to do pairing, mob programming, and designed a testing strategy as a reference.
- To adopt a feedback culture, using some patterns of sociocracy, such as circles (technical chapter, product circle), double linking, and other instruments such as Brown Bags, Community of Practice, Newsletter, Technical Blog and why not, the SDSummit.
- To encourage love for the product, promoting the refactor as a habit, for example.
Knowing our domain

We also saw that we needed to improve our knowledge of our own domain, in order to better structure our product teams. This was a process that we adapted as we advanced on it:
- First we enumerated all the functional leafs or product artifacts, grouped by initial technical categories, that we could not call domains yet.
- Later, we saw that we could use the Impact Mapping technique to align our artifacts with the business vision, to achieve that we defined:
- The Objective, the goal or the Why are we doing this?.
- Actors (clients, sales representatives, support, product teams), who participate in those objectives.
- Impact of these objectives on the actors.
- Functionalities that we had available to address these impacts, here we used the product artifacts that we had identified at the beginning of the process.
- When we finished with the Impact Mapping, we understood the system better and also found opportunities for improvement, and new tools that would help solve some problems.
- The next step was to group the artifacts, using actors as reference, and define the relationship between the artifacts (through APIs, databases, events or nugets). At this point we could already call those categories, domains.
- Then we modeled use cases, using Domain Message Flow Modeling. In a given use case, an actor initiates the flow, and the intervening domains are included, we validated that our proposal was correct or if we had to adjust it.
- Next, we differentiated the domains into three types: Core domains, where we grouped the functionality that differentiates us; Supporting Domains, which is vital for the functioning of the core, but does not provide differentiation; and Generic Domains, which are generally candidates for outsourcing
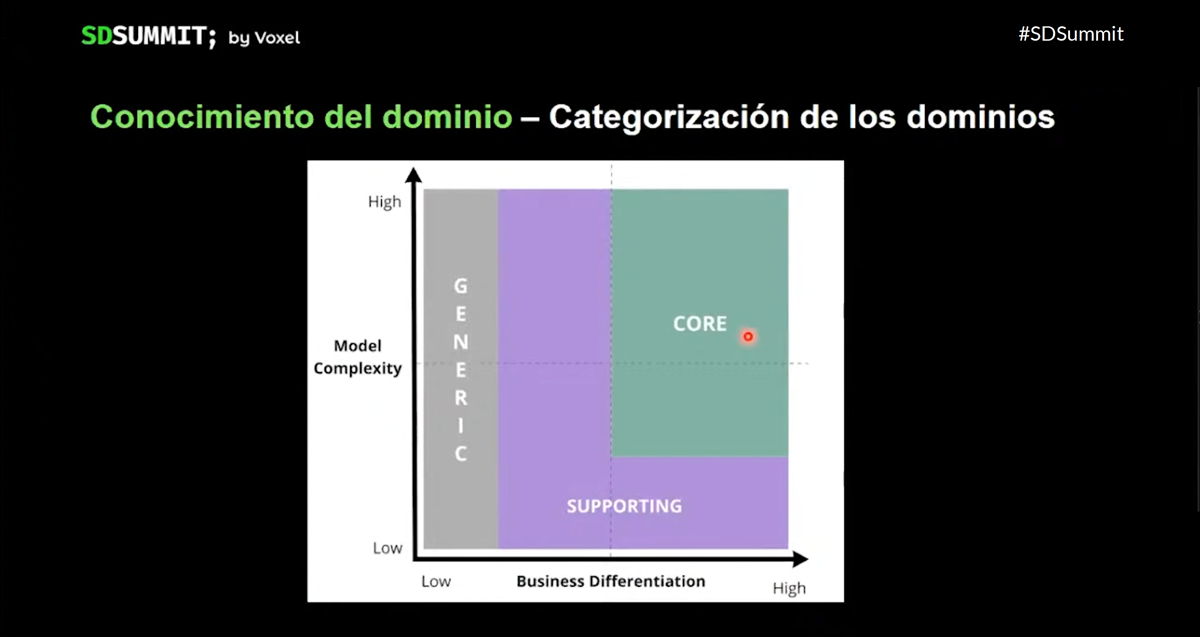
Improve our platform
Once this step back to better understand our domain was completed, we came back to focus on improving the platform, starting first with our core, it was time to refactor our legacy!
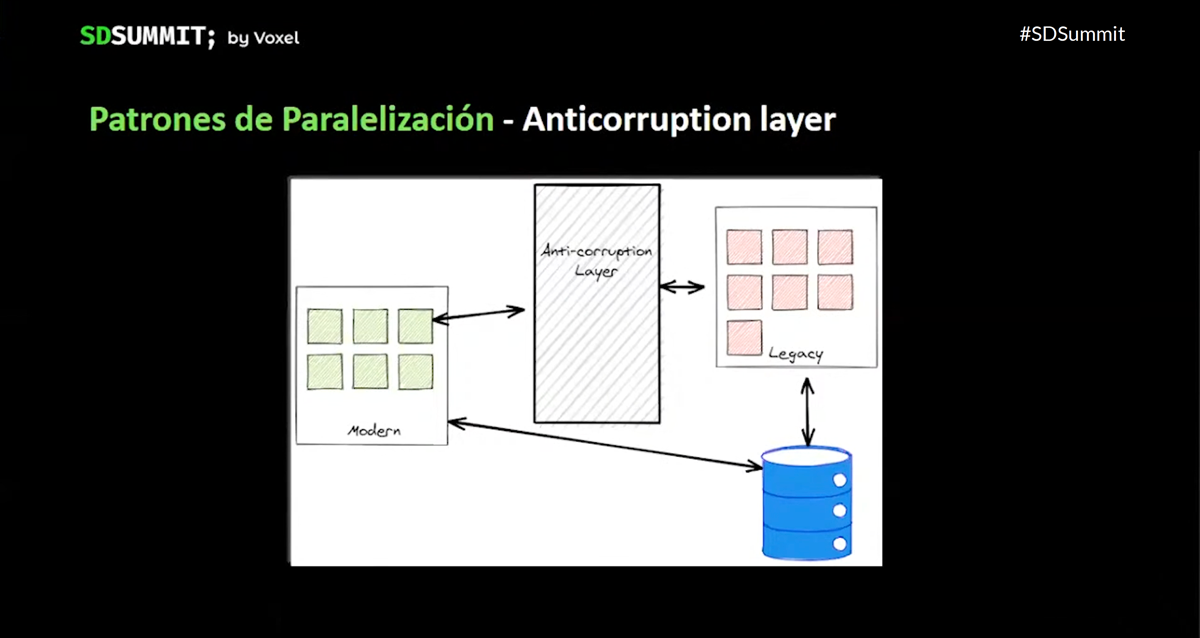
For this we planned and prioritized tasks to increase our test coverage, redirect our current architecture to one that better supports the DDD model and better define our contracts / interfaces. At this moment, we keep in mind that we will not rewrite everything from the beginning, so what do we do? We decided to use different parallelization patterns:
- Anti-corruption Layer, which translates the legacy for us so that it can communicate with new functionalities that better comply with a DDD model.
- Feature Toggles, allow us to have code quickly in production, even if it cannot be delivered to the end user yet, or that we want to deliver to specific users only. We must be careful, as the complexity can rapidly increase.
- Strangler Fig Pattern, as we heard from Carlos Blé in his talk, allows us to migrate in parallel, so we are able to upload complicated changes in small steps, and that we can test at each step. If it’s a long-haul migration, it’s important to make a commitment to finish it.
- Branch by abstraction, like the strangler pattern, but on a more internal level. We create a component-level contract, which prevents us from deviating from that contract while we migrate the implementation one step at a time.
What have we learned?
After discovering, planning, prioritizing and starting to carry out our plan, what have we gained? We have noticed that the skills of the product development teams have grown, both technical and cultural, we have learned to share and learn. We also know our domain much better, and on the way to discover it, we have learned to use tools like Impact Mapping, for example. In addition to knowing our domain better, now we also know where to focus efforts, and achieve the best impact. Finally, when tackling such a big task, in order to do it gradually, we have learned to use parallelization tools, approaching the legacy refactor in a manageable, safe and continuous way.
In summary …
And if we now stop and look at the road traveled, what conclusions can we obtain? Encouraging the culture of caring for our product is very important, feedback (human and technical) is essential, we need to work together between the business and technical areas, the size of our refactor User Stories must be of an acceptable size, we have to focus efforts on our Core Domains. And we must be able to do so without disrupting the normal operation of the system. Without a doubt, everything learned (techniques, culture, patterns, tools) will help us to continue improving!
The video of Xavi’s talk is now available. I encourage you to watch it! Congratulations for the talk Xavi!
About the author:







