

Like other terms used in software development, the concept of observability has its origin in another field, in this case, it is control systems. As the mathematical dual of controllability, the property that indicates whether the behavior of a system can be controlled from its inputs, observability is the property or the measure of how well the internal states of a system can be inferred from its external outputs. In other words, observability is ownership: it is about enabling us to own our code, own our services, own our availability. It is about fully understanding our systems.
As Charity Majors explains in Observability — A 3-Year Retrospective, it is important to know about how we have been trying to understand our systems and the changes that have taken place so far to understand why observability is interesting (and necessary) and why especially now.
Concepts
Is it said that observability can be achieved by building three pillars: metrics, logs and traces:
- Metrics are measurements, numerical representations of something measured in time intervals, and as such they can be aggregated. They allow us to generate histograms, counters, etc. but they do not usually have a rich or broad context linked to them. They generally indicate what and when something happened, but do not provide detailed information as to why. For the latter we usually resort to logging.
- Since the existence of terminals and high-level languages there have been logs, there have been string outputs that are readable and understandable for most human beings. These logs usually carry more detailed information on what and when something happened.
- Finally, we have traces, which in the end are like structured logs with an associated context. These traces are generated from the process of tracing, the following of a request from its beginning to its end that allows us to know what components and services are being used in our application. This makes it easier for us to highlight inefficiencies, bottlenecks, challenges in the user experience and so on.
So does observability consist of these three pillars? We would urge you to say “no”. In the end, these are just three types of data, with which we may or may not achieve observability. We can convert traces into time series metrics, metrics into logs and so forth. What matters is what you do with the data, not the data itself. Ben Sigelman explains it better in Three Pillars with Zero Answers.
Observability and monitoring
At this point, perhaps the question about the relationship between observability and monitoring has already arisen. Is monitoring observability? If it is monitorable, is it observable?
When monitoring, at least at its origin (and the word already says so), we look at monitors. We look at a series of panels that tell us what state our systems are in from predefined sets of telemetric data. When an anomaly occurs and we try to figure out what is happening, we are not really inspecting what happened by following a sequence of clues, we are jumping directly to an assumption:
“I look at my panels. I see a peak of errors at X o’clock. How weird (and how bad). It seems to occur on a particular Y cluster. Ah, the last time this happened, it was because Z was running. I’m going to check for something similar to Z. Look, here it is. Confirmed”.
As Charity Majors explains in her retrospective, it is as if the entire system still were one big black box. In a mental process like the previous one, we rely on multiple intuitive leaps and on a sort of mental library built by the experience of past incidents. We have to know the possible causes and know what to ask in advance when we look at the data.
Perhaps there is another process we could follow. Perhaps we could start by simply asking ourselves “what happened?” and systematically follow the data crumbs from there to the verifiable solution, whatever that may be. Majors explains that, in the end, what this implies is having little testable or refutable hypotheses one after the other, and that only works because we can drill down all the dimensions, it works because we have collected the data at the correct level of abstraction (which is difficult when we work with low cardinalities and if the data is aggregated prior to writing it, which is what usually happens with metrics).
Monitoring is useful when we can predict most of the states that our systems can be in, it is effective when the possible unknowns are a known stable set.
However, we know that this is less and less common: serverless, lambda functions, containers and microservices…The most difficult thing now is not understanding how the “problematic code” is executed, but finding where it is. For a system with predominantly unknown unknowns, monitoring tools are not enough. Monitorable is not observable.
Charity Majors elaborates more on the importance of clearly defining the concept of observability in the most recent Observability — The 5-Year Retrospective.
Conclusions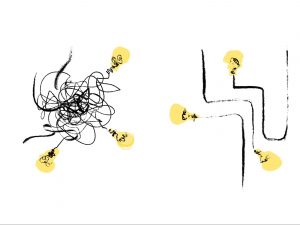
So what is an observable system? A system is observable when we can explain the unknown unknowns by following a thread that is already there. Observability is understanding the system without having to guess, without having to struggle trying to match patterns and without having to deploy new code to understand those unexpected new states.
Avoiding these blind procedures, avoiding having to deploy just to know something specific at a specific moment, avoiding breaking heads, etc., saves us time. And that is time that we can invest in developing, improving and really adding value.
To think about observability is also to think about curating the information so as not to have useless data that consumes resources unnecessarily. To think of observability is also to think of a democratization process: not only developers, engineers or people with a technical profile who know about complex telemetry data should understand what is happening. The value of observability is really evident when the entire organization can get the answers to their questions and understand how our projects, our services and our products work.
About the author
Carolina Zhou, Software Engineer at Voxel. Linkedin. Twitter.







