
Last October we attended the Software Crafters Barcelona event, and we were there in person! 🥳
We were really looking forward to such an event. We had missed sharing beers with colleagues and having those hallway conversations (the best conversations) that lead us to the most interesting topics. It most definitely did not disappoint and we had a great weekend!
This time we wanted to talk about observability. It is something that we have tried to work on and introduce in our day to day tasks at Voxel and we believe that no organization should neglect such an important subject.
We titled our talk “Understand your systems with OpenTelemetry” and we divided it into 5 parts:
Need
We explained the need that arose at Voxel to change the way of understanding our systems as a result of increasing difficulty in bug resolution. As an example, we mentioned that we had disparate information in unstructured logs, which in turn were on servers that were not always easily accessible. That is if those logs even existed.
Observability
Observability is a concept that has been mentioned a lot in the past few years, but its definition may vary depending on the source. The common denominator seems to be the idea that it is something that makes it easier for us to understand our systems. But how?
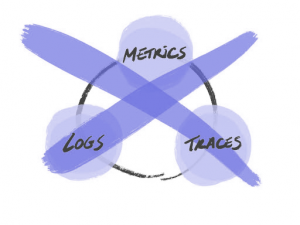
Over time, it has become popular and somewhat established that to have observability we need three main pillars: logs, traces and metrics. We did not want to reinforce the belief that there is a magic recipe with three specific ingredients. We cannot build and finish the “observability house” with just these so-called pillars and, as Charity Majors says, this thought can be an obstacle in the progress of observability tooling. Ben Sigelman also explains this in Three Pillars, Zero Answers: We Need to Rethink Observability.
We will also talk a bit about this in our future article on observability (coming soon!).
Experience
We exposed the first steps taken at Voxel to better understand our systems.
Within the technological transformation process, we have introduced centralized and structured logs, which are more accessible and searchables; canonical logging, which makes it easy for us to use “RED” metrics (Request Rate, Request Error and Request Duration); and correlated logs, which allow tracking through services. We also mentioned the creation and configuration of alarms and display panels for monitoring.
As we know now, this is not observability and the fact that we still have a way to go was emphasized
OpenTelemetry
 How can we start building this path towards observability from our applications? We all have different thought processes, we all work with different technologies…it is difficult to think of a tool that works for everyone, but it is already very difficult to think of a strategy that is consistent.
How can we start building this path towards observability from our applications? We all have different thought processes, we all work with different technologies…it is difficult to think of a tool that works for everyone, but it is already very difficult to think of a strategy that is consistent.
In this section we introduced the open-source OpenTelemetry project as an option to standardize the process of instrumentation, generation, collection and export of data from our systems.
Demo
Talk is cheap. Show me the code!
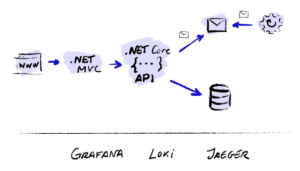
In this section we showed how we use OpenTelemetry in .NET projects along with other tools such as Jaeger, Loki and Grafana.
The demo is based on a user management website with access to a PostgreSQL database. When creating users, an event is emitted to an Azure Service Bus queue, consumed by a Generic Host Worker, which in turn sends an email informing that the user has been created.
Conclusions
We wrapped up by highlighting the benefits of using OpenTelemetry and encouraging people to reflect on the value of observability.
In the end, understanding our systems is not something that is of interest to technical profiles exclusively. Observability is ownership, and that enables us and makes it easier for us to make decisions at all levels of the organization.
We have started our journey and will continue to work on it. We encourage you to do it too!
About the authors
Xavier Belloso, Software Engineer at Voxel. Linkedin. Twitter.
Carolina Zhou, Software Engineer at Voxel. Linkedin. Twitter.




