
Make your systems use more cache
Introduction
As technology advances, web and desktop application users are becoming more impatient, getting used to having everything instantly.
Just a few years ago we didn’t mind waiting more than a minute to download and view any image from our browser.
But now this would be unthinkable. Technology has accustomed us to immediacy, and if our application does not meet the user’s expectations, we may lose sales, customers, or visibility.
According to some data collected by the Website Hosting service, in 2019 47% of users expected a web page to load in 2 seconds or less. Pages loaded in this time have a conversion rate of 1.9%, against those that load in 6 seconds or more, which have a low conversion rate of 0.6%. You can consult this complete study here.
But don’t panic, consumer requirements have increased, but also the available tools and technologies did so to meet these needs. One of the weak points in terms of processing speed for both web and desktop applications is relational databases. When these have thousands of queries and millions of records they can be ‘slow’, but is it necessary to go to our database to look for the same data over and over again? Could we save queries to our database, and therefore improve load times? Our friend, a cache, can help us with this.
But let’s start with the basics:
What is a cache and what is it for?
A cache serves as a high-speed data storage. It stores copies of the most frequently used data temporarily, so that subsequent requests can be handled faster than if they were accessed from the main storage.
When designing a cache, in order to maximize its efficiency, it is important to take into account the number of times the requested data is cached, i.e. the ratio of hits/misses. This is not a standard and will depend on the use case, but an ideal hit ratio is around 95-99%.
As mentioned above, the cache stores data temporarily, known as TTL (Time To Live), which is nothing more than the time the data will be in cache before it is deleted. It is important to think carefully about this parameter, since the efficiency of the system will largely depend on it.
Below, we can see a couple of simplified systems, one without cache, and another one with cache, to see how they work and what advantages they have:
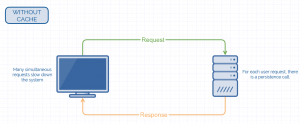
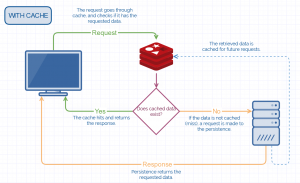
The cache has many use cases, among others:
- Increasing the speed of the database management system. Relational databases are “slow” when working with millions of records. Unnecessary or old data can slow down the index, and you may experience delays and latency in responding to a query. In these scenarios, read queries can be cached for a small period of time. Relational databases also use their own cache. This is one of the most popular use cases for caching.
- Query management in web/mobile applications. Web or mobile applications with a lot of traffic experience many calls to the backend, which usually end up being database read queries. Calls such as calculation on payments already made, non-critical dynamic data such as the number of followers of a user, number of retweets, number of viewers watching a live stream, etc. Caching is often used in these cases to ease the load.
- Video games. The player profile and leaderboard are 2 windows that players see very frequently, especially in online multiplayer games. With millions of players, it is extremely important to update and retrieve this data as quickly as possible. Caching is very effective in these cases.
- Caching in web pages. To make the interface of a mobile or web application lightweight and flexible, dynamic web pages can be created on the server and served through the API along with the appropriate data. If this application has millions of users, complete web pages created from cache can be published.
What is Redis
Redis is an open source in-memory database engine, based on key/value table storage where each key has its associated value. One of the main differences with other similar systems is that Redis supports the storage of more complex and flexible structures. Besides being able to store strings, it allows the storage of lists, or hashes useful to represent objects, among others.
Redis normally stores information in RAM memory, but allows data persistence through snapshots to enable data recovery in case of failures. Because the information is stored in memory, rather than on disk, data access times are far superior to traditional relational database access times.
In short, Redis is highly recommended when access speed and response time are critical to the business, or when working with a real-time application, making it an optimal choice for use as a cache.
Usage and implementation in a netCore project
We are going to show an implementation of a basic get/set against Redis in a netCore project. In this example, we are not going to focus on implementation details, we will only show the minimum and advisable, according to our experience, to be able to cache data on Redis.
First, we will install the NuGet Microsoft.Extensions.Caching.StackExchange Redis package. This library contains an implementation for using the .Net IDistributedCache interface with Redis as a caching backend. The IDistributedCache interface provides the necessary methods to manipulate elements in the distributed cache implementation, such as Get, Set or Remove.

Once nuget is installed, we must add the service in our Startup.cs:
startup.cs
services.AddStackExchangeRedisCache(options => options.Configuration = Configuration.GetSection("ConnectionStrings")["RedisServer"]);
services.AddSingleton(serviceProvider => new DistributedCacheInterceptor(serviceProvider.GetService(), serviceProvider.GetRequiredService()));
In this code snippet we can see 2 parts:
- services.AddStackExchangeRedisCache(options => options.Configuration = Configuration.GetSection(“ConnectionStrings”)[“RedisServer”]);
- Here from the settings file, we are adding the connection string of our Redis server to the caching service.
- services.AddSingleton<IDistributedCache>(serviceProvider => new DistributedCacheInterceptor(serviceProvider.GetService<RedisCache>(), serviceProvider.GetRequiredService<Serilog.ILogger>()));
- In this code snippet we add the cache service to our application. To highlight the class we are using to intercept this service: DistributedCacheInterceptor. This step is not necessary but highly recommended, since it allows us to intercept all calls to Redis from a single class without great effort.
Instead of doing it on each Get made in our application, it will be enough to have it centralized in our interceptor. This class should implement IDistributedCache. A possible use could be:
- In this code snippet we add the cache service to our application. To highlight the class we are using to intercept this service: DistributedCacheInterceptor. This step is not necessary but highly recommended, since it allows us to intercept all calls to Redis from a single class without great effort.
DistributedCacheInterceptor.cs
internal class DistributedCacheInterceptor : IDistributedCache
{
private readonly IDistributedCache _cacheService;
private readonly Serilog.ILogger _logger;
public DistributedCacheInterceptor(RedisCache cacheService, Serilog.ILogger logger)
{
_cacheService = cacheService;
_logger = logger;
}
public byte[] Get(string key)
{
byte[] bytes = null;
try
{
bytes = _cacheService.Get(key);
_logger.Information("GetOperation");
}
catch (Exception ex)
{
_logger.Error($"GetError {ex}");
}
return bytes;
}
In this example right after doing Get against our Redis (_cacheService.Get(key)), a log record is written ( _logger.Information(“GetOperation”)). This would apply to all Gets of the cache that appear in the system.
Finally, all that’s left is to see how we attack the cache from our productive code. If we use dependency injection, it would be as simple as injecting IDistributedCache where we want to perform some operation against Redis, and call the method we need.
In the example we check if a data is already registered in cache. If yes, we recover the data of this one and we save the query to bbdd. Otherwise, we will obtain the value from the bbdd, but we’ll store it in cache so that the next access will be faster.
Let’s not forget that we have an interceptor class (DistributedCacheInterceptor) where the requests go through before reaching Redis, so it would not be necessary to perform all the common operations (such as writing to log) at this level.
MyClass.cs
public class MyClass
{
private readonly IDistributedCache _distributedCache;
public MyClass(IDistributedCache distributedCache)
{
_distributedCache = distributedCache;
}
private string MyFunction(string key, string value)
{
var cacheResponse = _distributedCache.Get(key);
if (cacheResponse != null){
value = Encoding.UTF8.GetString(cacheResponse);
}else{
value = GetFromRepository (key) ;
_distributedCache.Set(key, Encoding.UTF8.GetBytes(value));
}
return value;
}
}
Alerting and observability
An important part of the system implementation is to keep track of its behavior. In the case of a cache, it is important to monitor elements such as hit and miss ratios or the correct configuration of TTLs.
If we want to monitor the stability and load of Redis, we have several options. In our case, we use RedisInsight, Grafana and Zabbix. Let’s take a look at each of them:
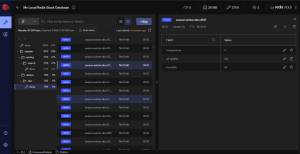
RedisInsight
This tool from the Redis team allows us to visualize and even modify the data in the cache. It allows us to interact via console or interface from the software itself, and to have saved several connections to different instances.
Grafana
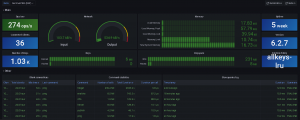
Grafana is an open source observability platform, where we can monitor systems and extract metrics from an infinite number of sources. In the case of Redis, we have it very easy because there is a plugin that facilitates the connection system to a Redis instance, and automatically mounts the control panel. It should be noted that Grafana allows us to create alerts that we can receive both by email and by other channels like Telegram or Slack.
Zabbix
Zabbix is designed for monitoring network services, servers and hardware. With this tool we can see the health status of the host where our Redis is hosted, being able to see a lot of data and as in Grafana, we can also create alerts, such as phone calls or messages by email or messaging systems.

Conclusions
Definitely, we have seen how a cache helps us to ease the burden of persistence, especially in systems under a lot of stress. Redis is an ideal candidate, since it is stored in memory, making it a very fast cache, and its implementation is quite simple.
We have also seen tools which help us to provide observability and create alerts. Now you just need to try it out.







